
Consulting, convening, coding, covering new ground, plus occasional commentary.
coding
Every Candidate Unplugged
Unpacking our experimental municipal election candidate tracking platform
(Scroll down to continue reading)
What started as the glimmer of an idea in 2010, slowly turned into a reality over a three stolen weekends this summer. From there it was blood, sweat and tears all the way to election day.
Curious how the money in elections works? We've done some of the math: http://t.co/sbvwDJcgKH #TOpoli #TOcouncil #FollowTheMoney
— Every Candidate (@EveryCandidate) October 23, 2014Three months ago, I launched the first Every Candidate site with my colleague, Tim Groves, a Toronto-based investigative reporter that I met while organizing a Canadian national media alliance several years ago.
As I wrote shortly after the site was launched: Every Candidate was kicked out the door later than I had hoped, and even calling it a “minimum viable product” was probably a stretch, but – in the spirit of “done is better than perfect” – it was alive, out in the world, and what we believed to be the most complete set of information on the 358 candidates who were running for city council across Toronto’s 44 wards.
Perfect is the enemy of good
Like all well-intentioned sketches of a wild-eyed, data-driven project, Every Candidate as originally envisioned was a behemoth even before the first line of code was written.
Thankfully, that version was never built (blame those every-demanding constrains: time & attention).
Thus, to get some momentum it had to start quite simply, as most successful products do. I sat down one weekend in late April and wrote a scraper for the City of Toronto’s candidate information pages. Like so many city data sets, the city site didn’t make it easy for visitors to get at all of the information, so a scraper & an online spreadsheet solved that problem.
Testing the idea, finding an audience
Next was the question: does anyone really care? To answer this question, I wanted to test the waters quickly and with the minimum possible effort. That meant that a full-blown Web site was pretty much out.
Given the generally positive response to news bots, I decided to put together a simple Twitter bot that would announce when candidates registered, and withdrew, and the ward involved. After a few funny misfires, it worked:
New nomination for councillor in #Ward13 in #Toronto: István Tar (2 May 2014). Got tips? Send them our way. #TOpoli #TOcouncil
— Every Candidate (@EveryCandidate) May 2, 2014It also announced a candidate count down in the days, hours, and minutes leading up the registration cut-off date.
353 candidates registered to run for city council. Just 1 minute to go until nominations close. #TOpoli #TOcouncil
— Every Candidate (@EveryCandidate) September 12, 2014Information bots are fairly addictive: they are simple to build, infinitely expandable. I could have easily focused 100% of my attention on just the ideas that bubbled up while thinking about what an information bot could accomplish during an election.
Going analogue

All that nerd-satisfying itch-scratching stuff aside, the real work got underway in earnest when Tim set out to gather information on the 358 candidates that was out of the reach the automated scraper: the databases & paper records at city hall.
Spending hours in the belly of the beast and making all kinds of friends, Tim worked tirelessly to manually transcribe information from the candidate’s registration forms (which some candidates seemed to believe were not public information), the city’s lobbyist registry database, and other systems only accessible from city hall.
Tim’s work resulted in some of the most successful posts on the Every Candidate site, like this one on where candidates lived and this one on the lobbyist registry. Working with Tim was an eye-opener and I highly recommend you try it – he’s unstoppable.
By the numbers
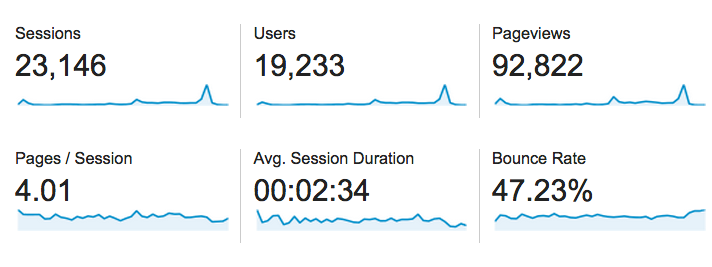
Here are some other interesting take-aways of the project:
- The site attracted 23,146 sessions from 19,233 users that resulted in 92,822 page views over a period of six weeks The biggest spikes in traffic were, not surprisingly, election day (5000+ sessions) and being interviewed on CBC’s metro morning.
- The average session spanned four pages and lasted two and a half minutes
- The return rate was almost 20%, which surprised me quite a bit (that’s almost 5,000 visitors that returned to the site at least once after their first visit)
- The average “engaged time” for the site was somewhere between one and two minutes, which is quite high compared to many news sites
- Twenty percent of the site’s traffic was mobile, and ten percent tablet
- “Organic search” drove more than 70% of the traffic to the site, more than direct traffic, social, or referrals.
- Of referral traffic, the top five referrers were Twitter (probably from the @EveryCandidate account), metronews.ca, torontolife.com, thestar.com, and choicestorm.com (thanks!).
Last but note least, there were just under 200 commits to the Every Candidate repository on Github (admittedly, many were just update to the data files), but at least 10% of those were from one or two volunteer contributors – the open-source software philosophy at work!
So, what’s next…
The obvious question is: would we do it again? It’s an interesting question…
I’m writing this post from Vancouver, where yesterday – Saturday, November 15th – was “General Voting Day” for local elections throughout British Columbia. That means nearly 150 municipal elections happened almost simultaneously, not to mention the elections for regional districts, island trusts, park boards, and school trustees.
Thinking about how to role out a project like Every Candidate for municipal elections in British Columbia is an interesting challenge to think about (glad there’s a few years before we need to cross that bridge!).
That said, I think that Every Candidate will likely make an appearance again at a more straightforward single-city municipal election in the near future. We’ll use that opportunity to continue to refine the model, evolve the software, and – more importantly – to do the research that helps to answer questions about who actually runs for public office.
If you want to know when we get started again, just follow Every Candidate on Twitter or join the mailing list.
About
Hi, I'm Phillip Smith, a veteran digital publishing consultant, online advocacy specialist, and strategic convener. If you enjoyed reading this, find me on Twitter and I'll keep you updated.
Related
Want to launch a local news business? Apply now for the journalism entrepreneurship boot camp
I’m excited to announce that applications are now open again for the journalism entrepreneurship boot camp. And I’m even more excited to ...… Continue reading
Previously
Beautiful Trouble Inc.
From the future
Putting #MediaInContext & Making Software